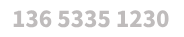
ę╗Īóā╚┤µöĄō■Äņ│÷¼FĄ─▒│Š░
ĪĪĪĪį┌é„ĮyĄ─öĄō■Äņ▒ĒųąŻ¼ė╔ė┌┤┼▒PĄ─╬’└ĒĮYśŗŽ▐ųŲŻ¼OLTPŅÉ▓┘ū„ę²ŲĄ─ļSÖC▓ķšęĢ■ĮoIOŽĄĮyĦüĒĖ▀░║Ą─ķ_õNŻ¼ę“┤╦é„ĮyĄ─▒Ē║═╦„ę²Ą─ĮYśŗįOėŗ×ķ╩╣ė├B-TreeČ°▒M┴┐£p╔┘ļSÖC▓ķšęŻ¼Ą½ė╔ė┌ÖCąĄ┤┼▒P║═öĄō■ÄņµiĄ─┤µį┌Ż¼B-TreeĮYśŗį┌╠Ä└Ē┤¾▓ó░lĄ─OLTPŁhŠ│ĢrŠ═’@Ą├ĘŪ│ŻĘ”┴”Ż¼ļm╚╗ėą║▄ČÓ▐kĘ©üĒĮŌøQ▀@ŅÉå¢Ņ}Ż¼▒╚╚ńšfśĘė^▓ó░l┐žųŲĪóæ¬ė├│╠ą“ŠÅ┤µĪóĘų▓╝╩Į╝▄śŗĄ╚Ż¼Ą½▓╔ė├╔Ž╩÷ĘĮ░ĖĢ■ī¦ų┬ą▐Ė─ę²ė├│╠ą“Ż¼▀@▓╗āH│╔▒ŠĖ▀Ūę’LļUśO┤¾ĪŻČ°ļSų°▀@ą®─Ļė▓╝■Ą─░lš╣Ż¼¼Fį┌Ę■äšŲ„ōĒėąÄū░┘Gā╚┤µ▓ó▓╗║▒ęŖŻ¼┤╦═Ōė╔ė┌ė▓╝■NUMA╝▄śŗĄ─│╔╩ņŻ¼ę▓Ž¹│²┴╦ČÓCPUįLå¢ā╚┤µĄ─Ų┐Ņiå¢Ņ}Ż¼ę“┤╦Š▀éõ┴╦╩╣ė├ą┬ĘĮ╩ĮüĒ╠Ä└ĒĖ³┤¾▓ó░l║═öĄō■┴┐Ą─Śl╝■Ż¼▀@ĘNą┬Ą─ĘĮ╩ĮŠ═╩Ū╩╣ė├ā╚┤µėŗ╦Ń╝╝ągĪŻ
ĪĪĪĪā╚┤µĄ─īW├¹Įąū÷Random Access Memory(RAM)Ż¼ę“┤╦╚ńŲõ╠žąįę╗śėŻ¼╩ŪļSÖCįLå¢Ą─Ż¼ę“┤╦ī”ė┌ā╚┤µŻ¼ļSÖC▓ķšę▓╗Ģ■ę²╚ļŅ~═Ōķ_õNŻ¼╩╣ė├Hash-Index▀@śėĄ─öĄō■ĮYśŗĖ³Ę¹║Žā╚┤µĄ─╠žąįŻ¼Č°ī”æ¬▓ó░lĄ─Ė¶ļxĘĮ╩Įę▓ī”æ¬Ą─ūā│╔┴╦MVCC(ČÓ░µ▒Š▓ó░l┐žųŲ)Ż¼Å─Č°Ž¹│²┴╦µię²╚ļĄ─ąį─▄Ų┐ŅiĪŻę“┤╦ā╚┤µöĄō■Äņ┐╔ęįį┌═¼śėĄ─ė▓╝■┘Yį┤Ž┬Ż¼╠Ä└ĒĖ³ČÓĄ─▓ó░l║═šłŪ¾Ż¼▓óŪę▓╗Ģ■▒╗µiūĶ╚¹Ż¼į┌SQL Server 2014ųąŻ¼╝»│╔┴╦▀@éĆÅŖ┤¾Ą─ā╚┤µöĄō■ę²ŪµŻ¼╚ń╣¹ĮY║ŽSSD AS Buffer Pool╠žąįŻ¼╦∙«a╔·Ą─ą¦╣¹īóĢ■ĘŪ│ŻųĄĄ├Ų┌┤²ĪŻ
ĪĪĪĪČ■ĪóSQL Serverā╚┤µöĄō■ÄņĄ─ĮM│╔║═▒Ē¼Fą╬╩Į
ĪĪĪĪį┌SQL Server 2014Ą─ā╚┤µöĄō■Äņę²Ūµė╔ā╔▓┐ĘųĮM│╔Ż║ā╚┤µā×╗»▒Ē║═▒ŠĄžŠÄūg┤µā”▀^│╠ĪŻļm╚╗ā╚┤µöĄō■Äņ╝»│╔▀M╚ļĻPŽĄöĄō■Äņę²ŪµŻ¼Ą½įLå¢ā╚┤µöĄō■ÄņĄ─ĘĮĘ©ī”ė┌┐═æ¶Č╦üĒšf╩Ū═Ė├„Ą─Ż¼▀@ę▓ęŌ╬Čų°Å─┐═æ¶Č╦æ¬ė├│╠ą“Ą─ĮŪČ╚üĒ┐┤Ż¼▓ó▓╗Ģ■ų¬Ą└ā╚┤µöĄō■Äņę²ŪµĄ─┤µį┌ĪŻ╚ńłD1╦∙╩ŠĪŻ
Ī°łD1.┐═æ¶Č╦APP▓╗Ģ■Ėąų¬Hekatonę²ŪµĄ─┤µį┌
ĪĪĪĪ╩ūŽ╚ā╚┤µā×╗»▒Ē═Ļ╚½▓╗Ģ■į┘┤µį┌µiĄ─Ė┼─Ņ(ļm╚╗ų«Ū░Ą─░µ▒Šėą┐ņššĖ¶ļx▀@éĆśĘė^▓ó░l┐žųŲĄ─Ė┼─ŅŻ¼Ą½┐ņššĖ¶ļx╚į╚╗ąĶę¬į┌ą▐Ė─öĄō■Ą─Ģr║“╝ėµi)Ż¼┤╦═Ōā╚┤µā×╗»▒ĒHash-IndexĮYśŗ╩╣Ą├ļSÖCūxīæĄ─╦┘Č╚śO┤¾╠ßĖ▀Ż¼ā╚┤µā×╗»▒Ē▀Ć┐╔ęįįOų├×ķ╩╣ė├ĘŪ│ųŠ├╗»╚šųŠŻ¼╝╚öĄō■╝╚▓╗īæ╚šųŠŻ¼ę▓▓╗Ģ■CheckPointĄĮ┤┼▒PŻ¼Å─Č°śO┤¾Ą─ĮĄĄ═┴╦IOē║┴”(▀m║Žė┌ETLųąķgĮY╣¹▓┘ū„Ż¼╗“š▀Ųõ╦¹į╩įSüG╩¦öĄō■Ą─ł÷Š░)Ż¼▀@śėę╗üĒę▓┐╔ęįŽ¹│²īæ╚šųŠę²╚ļĄ─ąį─▄Ų┐ŅiĪŻ
ĪĪĪĪŽ┬├µüĒäōĮ©ę╗éĆā╚┤µā×╗»▒ĒŻ║
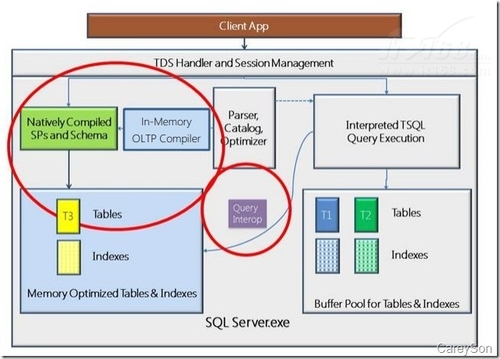
ĪĪĪĪ╩ūŽ╚Ż¼ā╚┤µā×╗»▒ĒąĶę¬öĄō■Äņųą┤µį┌ę╗éĆ╠ž╩ŌĄ─╬─╝■ĮMŻ¼ęį╣®┤µā”ā╚┤µā×╗»▒ĒĄ─CheckPoint╬─╝■Ż¼┼cé„ĮyĄ─mdf╗“ldf╬─╝■▓╗═¼Ą─╩ŪŻ¼įō╬─╝■ĮM╩Ūę╗éĆ─┐õøČ°▓╗╩Ūę╗éĆ╬─╝■Ż¼ę“×ķCheckPoint╬─╝■ų╗Ģ■īóą┬į÷Ą─öĄō■ĖĮ╝ėį┌ĄĮą┬Ą─CheckPoint╬─╝■Ż¼Č°▓╗Ģ■ą▐Ė─¼FėąĄ─CheckPoint╬─╝■Ż¼╚ńłD2╦∙╩ŠĪŻ
Ī°łD2.ā╚┤µā×╗»▒Ē╦∙ąĶĄ─╠ž╩Ō╬─╝■ĮM
ĪĪĪĪŽ┬├µį┘üĒ┐┤ę╗Ž┬ā╚┤µā×╗»╬─╝■ĮMį┌┤┼▒PŽĄĮyĄ─┤µā”ą╬╩ĮŻ¼╚ńłD3╦∙╩ŠĪŻ

Ī°łD3.ā╚┤µā×╗»╬─╝■ĮM
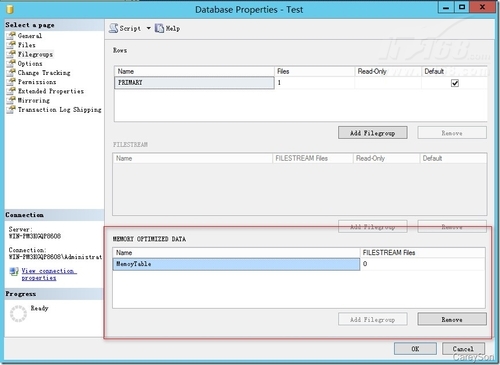
ĪĪĪĪäōĮ©═Ļā╚┤µā×╗»╬─╝■ĮMų«║¾Ż¼ĮėŽ┬üĒį┘äōĮ©ę╗éĆā╚┤µā×╗»▒ĒŻ¼╚ńłD4╦∙╩ŠĪŻ
Ī°łD4.äōĮ©ā╚┤µā×╗»▒Ē
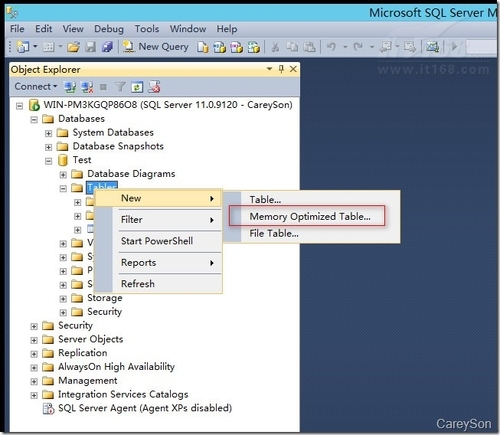
ĪĪĪĪ─┐Ū░SSMS▀Ć▓╗ų¦│ųUIĮń├µäōĮ©ā╚┤µā×╗»▒ĒŻ¼ę“┤╦ų╗─▄═©▀^T-SQLüĒäōĮ©ā╚┤µā×╗»▒ĒŻ¼╚ńłD5╦∙╩ŠĪŻ

Ī°łD5.╩╣ė├┤·┤aäōĮ©ā╚┤µā×╗»▒Ē
ĪĪĪĪ▀@└’äōĮ©ę╗éĆ║åå╬Ą─ā╚┤µā×╗»▒ĒŻ¼▀@└’╔Ž╩÷įOų├Hash Bucket×ķ1024Ż¼─┐Ū░SQL Server 2014▀Ć▓╗ų¦│ųäėæBĄ─Hash BucketŻ¼ę“┤╦▒žĒÜ╩ųäėįOų├įōųĄĪŻ▒ĒųąįOų├┴╦Memory_Optimized×ķONęŌ╬Čų°▒Ē╩Ūā╚┤µā×╗»▒ĒŻ¼Č°DurabilityįOų├×ķSchema_And_DataätęŌ╬Čų°ā╚┤µā×╗»▒ĒųąöĄō■ę▓╩Ū│ųŠ├╗»Ż¼▀@ęŌ╬Čų°│²ĘŪåóė├┴╦SQL Server 2014Ą─čė▀tīæ╠žąįŻ¼öĄō■▓╗Ģ■ė╔ė┌«É│ŻŪķørī¦ų┬üG╩¦ĪŻ
ĪĪĪĪ«ö▒ĒäōĮ©║├ų«║¾Ż¼Š═┐╔ęį▓ķįāöĄō■┴╦Ż¼ųĄĄ├ūóęŌĄ─╩ŪŻ¼▓ķįāā╚┤µā×╗»▒ĒąĶę¬snapshotĖ¶ļxĄ╚╝ē╗“š▀hintŻ¼▀@éĆĖ¶ļxĄ╚╝ē┼c┐ņššĖ¶ļx╩Ū▓╗═¼Ą─Ż¼╚ńłD6╦∙╩ŠĪŻ
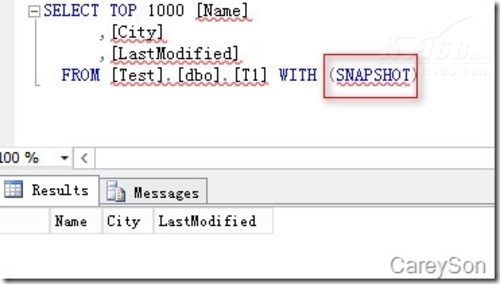
Ī°łD6.▓ķįāā╚┤µā×╗»▒ĒąĶę¬╝ė╠ß╩Š


